

Oracle的三种去重方法
oracle的三种去重方法
下面通过案例进行三种去重方法的分析:
公司统计人员信息,发放节日福利,部分人员存在多次信息录入,需要对数据进行去重:
表信息:
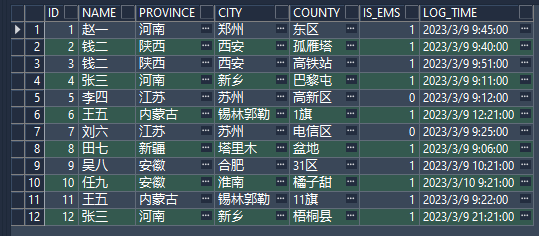
1、distinct
通过观察,可以通过NAME、PROVINCE进行去重,结果如下:
select distinct t.name, t.province from EMS_INFORMATION t; 但是多次填写的数据,需要以最后一次的填写记录为准,所以需要加上
但是多次填写的数据,需要以最后一次的填写记录为准,所以需要加上
select distinct t.id, t.name, t.province
from EMS_INFORMATION t
order by t.id;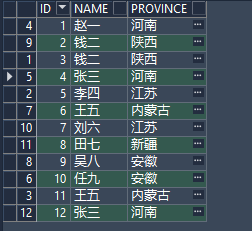 发现distinct同时作用了id,name,province三个字段,并未达到去重效果,只有id,name,province相同,才会去重
发现distinct同时作用了id,name,province三个字段,并未达到去重效果,只有id,name,province相同,才会去重
2、group by
也是先通过NAME、PROVINCE进行去重,结果如下:
select t.name, t.province
from EMS_INFORMATION t
group by t.name, t.province;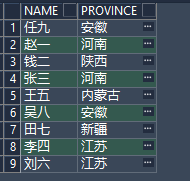 结果跟distinct一直,如果加上id会怎么样呢
结果跟distinct一直,如果加上id会怎么样呢
select t.id, t.name, t.province
from EMS_INFORMATION t
group by t.id, t.name, t.province
order by t.id;发现结果还是没有实现去重
3、row_number()over(partition by order by )
也是先通过NAME、PROVINCE进行去重,结果如下:
select *
from (select t.name,
t.province,
row_number() over(partition by t.name, t.province order by t.id) rn
from EMS_INFORMATION t)
where rn = 1;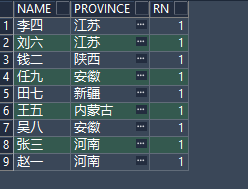 结果跟前两个一致,那么再加上id
结果跟前两个一致,那么再加上id
select id,name,province
from (select t.id,
t.name,
t.province,
row_number() over(partition by t.name, t.province order by t.id) rn
from EMS_INFORMATION t)
where rn = 1
order by id;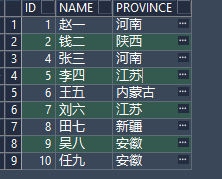 在加上其他字段试试
在加上其他字段试试
select *
from (select t.*,
row_number() over(partition by t.name, t.province order by t.id) rn
from EMS_INFORMATION t)a
where rn = 1
order by id;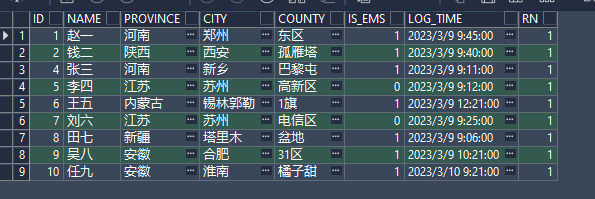
总结:
1、distinct常用来查询单列或者多列 不重复记录的行,可以使用count(distinct name)进行计数不重复行,但需要注意的,count()只能作用于单列
2、group by 常用于分组,可以搭配聚合函数(COUNT, SUM, AVG, MIN, MAX)使用;经常使用的有一个用法就是排查主键重复的数据
select id, count(1)
from students
group by id
having count(1) > 1;3、row_number()over(partition by column1 order by column1),将表中的记录按字段 COLUMN1进行分组,按字段 COLUMN2 进行排序,其中
PARTITION BY:表示分组ORDER BY:表示排序,去重就是利用分组排序生成的列rn进行去重
本文是原创文章,采用 CC BY-NC-ND 4.0 协议,完整转载请注明来自 ZFS的成长之路
阅读建议
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果